JMPファイルを何とかRに取り込もうとする…も撃沈する
0. はじめに
少し前から大学病院でJMP ( ジャンプ ) という統計ソフトの包括ライセンス契約を結んでいるらしく、JMPを使って解析をしたという話をよく聞くようになった。どうやら初学者にも使いやすくて好評らしい。聞いたことなかったので、なんだその怪しいソフトは、と内心バカにしていたのだが ( スミマセン ) どうやら泣く子も黙るSASの別バージョン ( ? ) らしい。
先日、共同研究先の先生から、jmpファイルで被験者情報のファイルをいただいたのだが、手元にRしか存在しないため上手く読み込めなくて悪戦苦闘してしまった。Excelに変換してもらう、というオチになってしまったが、その奮闘記を何かの役に立てればと思い書いてみる。
1. なぜExcelに変換してはいけないのか?
誰もが思うExcelにexportしてもらえばいいじゃん、ということ。当然僕も思いましたし、最終的にここに落ち着いてしまいましたが、
- カテゴリー変数のラベル情報が消去されてしまう
という致命的な問題があるようです。
2. JMPファイルをRで読み込むのは難しい
ネットで.jmpからRに取り込む手段を検索するもなかなかヒットしない。
どうやらRとJMPを同じマシンにインストールしておけばいろいろと連携させることができるようです。しかしそんなことがしたいわけではない。困ったのでFacebookのRのグループのメンバーにお伺いを立ててみた。すると、JMPでSASのファイルに変換すれば上手く読み込めるという情報をいただいた。コチラにも同様の情報がある。その名も、SAS移送ファイルで拡張子は.xpt。
3. .sas7bdat
3-1. {sas7bdat}を試してみる
というわけで、.xptに変換してもらうように先方に依頼したところ、.sas7bdatという形式で送られてきた。明らかにこれもSASのファイルなので、Rで開けるだろうと判断していろいろと調べてみるとRのPackage ‘sas7bdat’で開けることがわかった。
install.packages("sas7bdat") library("sas7bdat") Data <- read.sas7bdat("export.sas7bdat",debug=FALSE)
と入力すると
Error in read.sas7bdat("export.sas7bdat", debug = FALSE) : magic number mismatch please report bugs to maintainer
と返ってくる。エラーメッセージをgoogleにかけても有効な情報は得られない。辿り着いたコチラのサイトによると、どうやら原因は2つあるようだ。
■ SAS側でのデータ作成について
ASデータセットを作るときに圧縮をかけるのが通常なのですが、
Rに取り込むときに圧縮をかけていると、
読み込みがエラーになるので注意が必要です。⇒SASにて、データを取り込むときに「compress = no」とオプションをつける!
データの確認 日本語の変数要素が入っている場合は 文字化けしている可能性があります。
先方にデータを圧縮したか尋ねたが明瞭な回答は得られず。日本語はそもそも入っているようで、英語にすべて変換するのは厳しいとのこと。というわけで{sas7bdat}を使うのは諦めた。
3-2. {haven}を試してみる
次にたどり着いたのは、Package ‘haven’。これも試してみると
install.packages("haven") library(haven) read_sas("export.sas7bdat")
すると
read_sas("export.sas7bdat") Error: Failed to parse export.sas7bdat: Invalid file, or file has unsupported features.
と怒られた。するとhavenの最新バージョンならイケるという情報をゲットしたので試してみる。Githubからダウンロードするらしい。
devtools::install_github("hadley/haven") library(haven) read_sas("export.sas7bdat")
インストールに時間がかかり、これはイケるかも?と期待されたが
read_sas("export.sas7bdat") Error: Failed to parse export.sas7bdat: Invalid file, or file has unsupported features.
とあえなく撃沈。
3-3. sas7bdat.parso
今度はコチラのサイトを見つけました。ここで紹介されているsas7pdat.parsoという物を使えば、compressされたSASファイルも扱えそう。というわけでやってみました。
install.packages(c("rJava", "devtools")) devtools::install_github("BioStatMatt/sas7bdat.parso") library(sas7bdat.parso) read.sas7bdat.parso("export.sas7bdat")
とすると今度は
Error in .jnew("s7b2csvclass") : java.lang.UnsupportedClassVersionError: s7b2csvclass : Unsupported major.minor version 51.0
という新しいエラーメッセージが。割りとメジャーなものでどうやらJAVAの設定の問題の様子。Githubの皆様は、みんな困っていたようですが、解決策が出ず。他にもいろいろとgoogleでヒットするのですが、僕の理解の範疇を超えてしまっています。コチラを参考に.bash_profileをいじったりしましたが、結局解決せず。この問題さえ解決できれば、クリアできそうだったのに…残念です。
3. .xpt
というわけで、.sas7bdatのインポートは諦めて、改めて.xptで送ってもらうように頼みました。.xptであれば割りと有名なpackage ‘foreign’でインポートできるようです。
install.packages("foreign") library("foreign") mydata <- read.xport("export.xpt")
とすると、ついに読み込めました!感極まりましたが、結局、
head(mydata)[,1:6]
とデータを確認すると
> head(mydata)[,1:6] X_R______ X____ X___A X________ X_E______ X_E_____R 1 C001 2 1 1 0 NA 2 C002 1 1 2 0 NA 3 C003 1 1 3 0 NA 4 C004 1 1 4 0 NA 5 C005 NA 1 5 -1 NA 6 C006 1 1 6 0 NA
となり、日本語で書かれた列名が文字化けし、ラベルの項目は結局削除されてしまっていましたとさ。
というわけで、長くなりましたが、結局はExcelに単純に変換してもらったファイルを何とかラベルを類推して解析しました。恐らくsas7bdat.parsoでJAVAの問題さえ解決できればなんとかなったんじゃないかと思われます。
どなたか、詳しい方、教えていただけると幸いです。
予測メタゲノム解析: HUMAnNをインストールするためのあれこれ
はじめに

HUMAnNとは、The HMP Unified Metabolic Analysis Networkの略で、メタゲノムデータを使って腸内細菌叢がどの代謝経路を有していて、またその遺伝子をどれくらい持っているのか?ということを明らかにするためのパイプラインです。16SrRNAアンプリコンシーケンシングではできない、腸内細菌の機能の比較にまで踏み込んでいけます。
通常はメタゲノムデータ、つまり糞便中の全細菌の全DNAの配列を全て読んだ膨大なシーケンスデータを使って解析をしますが、PICRUStを用いれば、16S rRNA解析の結果をゲノムデータベースにマッチングさせて遺伝子を予測することができます。
続きを読むGasteroenterology: γδ-T 細胞から産生されるIL-17と胆道閉鎖症
Interleukin-17, Produced by γδ-T Cells, Contributes to Hepatic Inflammation in a Mouse Model of Biliary Atresiaand is Increased in Livers of Patients.
続きを読むOffice365のアカウント認証が上手くいかない
腸内細菌叢の成長: 生後1000日の変遷
わからない単語を英辞郎で検索するショートカットキーを作成する
はじめに
論文を読んでいてわからない単語が出てくると、みなさんどうしてますか?僕はMacのスクリーンで読むことがほとんどなので、三本指でタップすれば辞書.appが自動的に立ち上がってくれますが、専門用語だと載っていないことも多いです。
僕はアルクの英辞郎を愛用してます。皆さんご存知の通り、専門用語でもたいていの単語は載っていますし、それよりも豊富な例文が強みで、僕は有料会員登録もしてしまいました。 ( Weblioの方が音声ファイルは充実していると思います ) 調べた単語を単語帳に片っ端から登録し、週に1回復習をしています。
前置きが長くなりましたが、ショートカットで一発で英辞郎で単語の意味を調べられないかな?と思っていろいろ調べてみたところ、Automatorを使えば比較的簡単に出来そうなことがわかったのでやってみたところうまくいきましたので紹介したいと思います。
ちなみに英辞郎はMacの辞書.appに組み込むこともでき、昔は僕もそうやっていましたが、単語帳に登録できないことと、値段が高いこと、容量が1GBくらいあり、Macbook Airの容量を圧迫してしまうことから、この方法がbetterと考えます。
今回は、こちらのMacの右クリックメニューに項目を追加する方法の記事を参考させていただきました。
1. Automatorでワークフローを作成する
- Automatorを立ち上げる
- 書類の種類を選択してください→「サービス」を選ぶ

- 「ユーティリティ」→「クリップボードにコピー」をドラッグ&ドロップ

- 「AppleScriptを実行」→ドラッグ&ドロップ→下記のスクリプトを入力する
set aURL to "http://eowp.alc.co.jp/search?q=" & (get the clipboard)
open location aURL

- コンテキストメニュー ( 右クリックメニュー ) に表示したい名前をファイル名にして保存
 これでコンテキストメニューの「サービス」に「英辞郎で調べる」が追加されました。
これでコンテキストメニューの「サービス」に「英辞郎で調べる」が追加されました。
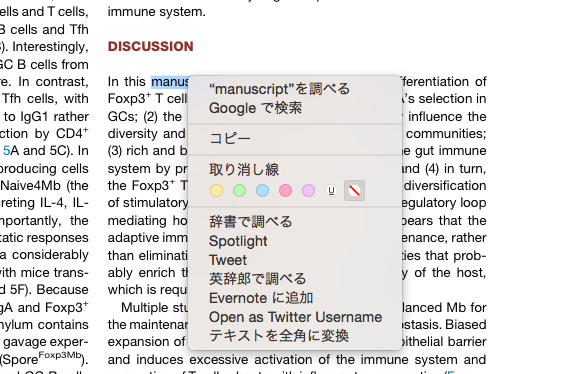
2. ショートカットの作成
「システム環境設定」→「キーボード」→「ショートカット」タブ→「サービス」→「英辞郎で調べる」で好きなショートカットを決める。僕は「control + command + E」にしてみました。

以上になります。ちなみにコンテキストメニューからだと「サービス」を選んでからでないと「英辞郎で調べる」にアプローチできず鬱陶しいので、Macの右クリックメニューを3倍使いやすくする方法まとめ。を参考にして、改善してあります。
プレビューで論文をPDF読んでるときでも、Safariでサイト開いている時でも、コンテキストメニューもしくはショートカットキー一発で英辞郎で調べられますのでかなり快適ですよ。オススメです、ぜひともお試しあれ。ちなみにApplescriptのURLの部分を工夫すれば、どんな検索サイトにも対応可能と思います。
Automator、かなり便利なのは前々から知っていたのですが、これを機に勉強してみたいなと思いました。
エラーバーとSDとSE
0. はじめに
エラーバーについて書いていこうと思います。エラーバーとは何かというと、棒グラフや折れ線グラフについているエ字の棒です。かっこいいグラフにはよくついているやつですが、きちんと意味を知っていることが非常に大切なことだと思いますのでまとめておきます。
続きを読む